利用CLIP模型做時尚穿搭資料庫搜尋
近年來,除了在單一領域如電腦視覺、自然語言、語音處理都開創了一片天地之外,深度學習也開始朝向multi-modal learning的方向延伸。Multi-modal 的意思是整合多於一種的資料類型共同做學習,就如同幼兒在探索世界時會同時接收到視覺、聽覺、觸覺…等多種感受的輸入,使得我們更能了解一些概念的不同面向(e.g. 白兔有著大耳朵與短尾巴,摸起來毛茸茸的)。而2020年OpenAI團隊提出的CLIP就是multi-modal learning的經典模型架構,也是今年當紅的"AI算圖"工具如DALL-E-2的基本架構,本篇文章將簡單介紹CLIP模型的概念與架構外,並且實際做一個穿搭資料庫的應用。
CLIP模型架構介紹

CLIP的目標是透過大量圖片與其文字描述,建立兩者之間的對應關係,如Figure 1. 所示,CLIP模型包含了幾個主要的部份。首先Image Encoder(圖中綠色部分)是CNN或是ViT等架構,目標為將圖片編碼成固定長度的向量(embedding),而Text Encoder(紫色部分,使用的是Transformer架構)則會將一段句子同樣編碼成相同長度的向量,並且讓相對應的圖片-文字兩向量相似度越接近1越好,而沒有對應的圖片-文字向量則相似度要接近0 (圖的右側為相似度矩陣),如Figure 1. 中總共有N張的圖片與相對應的N段文字,在取得圖片向量I與文字向量T後,我們會希望右側矩陣中淺藍色的部分(代表是對應的圖片-文字)數值為1,而其他灰色的部分(非對應的圖片-文字)數值為0。
訓練完成的CLIP模型有著明確的優勢,其Image encoder與Text encoder能夠將圖片與文字映射到同一個向量空間,因此可以直接計算圖片與句子的相似程度。若想將其應用到分類情境上,也只需要將不同類別的描述列出,並且計算圖片與哪個描述最相似即可(如Figure 2. 所示),可直接達到零樣本學習(zero-shot learning)的效果。針對CLIP架構較詳細的描述與應用,建議大家可以參考OpenAI的官方部落格文章。

CLIP應用實作
接下來,我們將會使用OpenAI釋出的CLIP預訓練模型,做到以文字搜尋資料庫中圖片的效果。本次使用的範例資料為Yang et al. 2014年於CVPR發表的資料集,其中共有1000張真人於室外拍的全身照(範例請見Figure 3.),在原資料集中也包含了這1000張照片中各個衣物部件的語意分割標籤,然而在本次的應用中不會用到標籤的部分。
我們會把這個資料集作為穿搭的參考依據,根據我們輸入的服飾特徵描述,找出相似度最高的照片並呈現出來(用法與google圖片搜尋非常類似,但此方式與google背後的演算法機制不全然相同),一起來看看CLIP能做到什麼程度吧!
關於資料集的更多說明請參考kaggle連結。

實作流程依序為
- 載入CLIP預訓練模型
- 將1000張圖片透過Image Encoder轉換為1000組向量
- 根據我們想搜尋的文字描述(prompt),利用Text Encoder同樣轉換為1組向量(這個用來查詢的向量被我們稱為query)
- 將query跟1000組圖片向量計算相似度
- 找出前k個相似程度最高的圖片作呈現
實際看一下我們能夠在資料庫中搜尋到什麼穿搭。首先,假設我下個月要去參加一場重要的活動(e.g. 研討會或婚禮),因此我以” Formal clothes for man.”作搜尋,可以看到CLIP的確幫我們找到資料庫中一些偏向正式的衣服,但可能是國外的穿搭比較前衛一點,長袖配短褲的部分我還是不敢貿然嘗試。

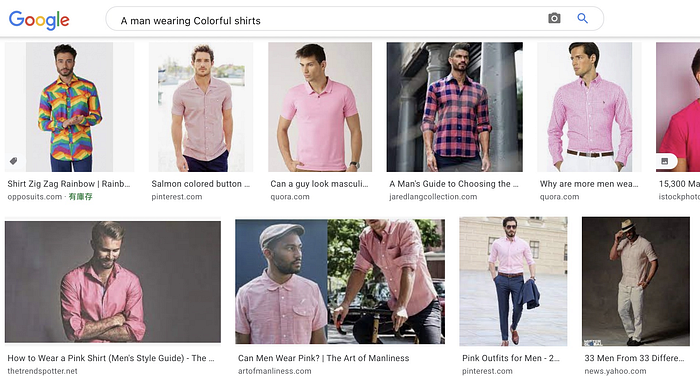
但看到上述的穿搭,我也想挑戰一些比較大膽的風格,因此我再以”A man wearing Colorful shirts.”當作搜尋關鍵詞,這次出現的幾套穿搭的確是可以考慮敗下去的。

有趣的是,若將同樣的句子丟到google圖片搜尋,反而大部分得到粉色系的襯衫,也許google對colorful的定義比較特別一點XD(note : 由於google搜尋資訊會持續更新,也許大家後續嘗試所得到的結果會跟我不一樣)。
接著,我甚至也想考慮除了衣著外連造型都換一下,由於CLIP並非只考慮服裝的描述,因此我也可以放入更多說明,這次我選擇的輸入是”Man with beard, wearing stylish clothes.”,除了要留鬍子我還想穿的潮一點。的確我看到許多潮男,不過似乎他們的帥與衣著無關,跟長相好像比較有關聯…

想看更多不同的搜尋結果嗎?



可以看到,無論我輸入特定顏色、比較抽象的描述(穿的像貓的男人)、或是直接形容環境狀態(冷冷的下雨天),的確都得到精準度蠻高的結果,也代表CLIP某個程度上的確能根據我們給與的文字描述找到類似的圖片。也歡迎大家嘗試輸入其他的描述內容並且試著玩玩看這樣子的應用。
總結
CLIP在整合文字資訊與圖像上做了非常大的突破,也能透過描述文句找到相對應的圖片,然而研究團隊也發現要找到一個適當的句子並不是那麼的容易,概念非常相似的句子也可能在結果上有一些差異(在上述的應用中大家也可以嘗試用不同的句子描述相同的概念並且觀察一下結果),針對要分類/搜尋的文句做設計(研究團隊稱之為prompt engineering)反倒成為後續需要較多人為介入的部分。另外由於CLIP中訓練資料主要是較為廣泛的圖片與句子配對,因此若是希望拿CLIP模型用於較為精細或領域專業的分類問題(fine-graind classification problem)則可能就沒辦法達到那麼好的效果,而CLIP較不擅長的內容還包含了較為抽象的任務(例如文句中有提到數量相關的描述CLIP時常沒辦法精確地理解)。但無論如何,CLIP的確可以說是深度學習中的一個重要里程碑,也期待能看到更多CLIP延伸的應用以及多模態學習的領域上有趣的進展。
